

Impara cos’è Big Data e come iniziare subito con gli strumenti più adatti

Che cosa è Big Data?
Il termine Big Data è diventato ultimatamente molto popolare, ma il suo significato – oltre a non essere sempre chiaro ai più – assume spesso aspetti diversi. In linea generale, possiamo riassumere il suo significato come il modo di trattare cospicui volumi di dati in costante aumento, azione che richiede strumenti di raccolta, storage e analisi differenti da quelli tradizionali.
Qualche esempio? I dati presenti nei social media come Facebook e Twitter ma anche la raccolta dei dati prodotti dai sensori degli aeroplani, ossia GB di dati prodotti ogni secondo…
Quindi, quali soluzioni permettono di gestire ed elaborare questa mole di dati?
In questo articolo parleremo degli strumenti alla portata di tutti, installabili su un server in hosting o anche su un server virtuale: i database NoSQL.
Che cosa è NoSQL?
Il termine “database” è stato a lungo sinonimo di SQL o meglio di RDBMS, e – per almeno quattro decenni – sembrava che non ci fosse alcuna alternativa praticabile. Recentemente, tuttavia, il mondo della memorizzazione dei dati ha a disposizione una nuova ed interessante possibilità: NoSQL.
NoSQL sta per “Not Only SQL” e questo sottolinea che la tecnologia NoSQL non è del tutto incompatibile con SQL (Structured Query Language), anzi, in alcuni casi è possibile utilizzare lo stesso linguaggio SQL per interrogare i database NoSQL, seppure con alcune importanti limitazioni come le JOIN.
Il database NoSQL ha avuto il suo inizio come una soluzione in-house per risolvere problematiche sperimentate da aziende di grandi dimensioni come Google, Amazon e Facebook. Inizialmente, queste aziende hanno cercato di risolvere i loro problemi con SQL, ma ben presto hanno scoperto che ciò non poteva soddisfare le loro esigenze e si sono scontrati con tre requisiti fondamentali:
- Volumi delle transazioni senza precedenti
- La necessità di bassa latenza di accesso ai set di dati enormi
- La disponibilità del servizio quasi perfetto, nonostante l’ambiente selvaggiamente imprevedibili
Perché usare NoSQL?
NoSQL non è sicuramente indicato per tutti gli utilizzi e non è un rimpiazzo dei database RDBMS tradizionali, ma può affiancarli o in parte sostituirli, e i suoi vantaggi principali lo rendono utile, se non addirittura indispensabile, in alcune occasioni.
Quali sono i vantaggi di NoSQL?
Rappresentazione dei dati senza schema
Quasi ogni implementazione NoSQL è libera della necessità di schema, perciò non c’è bisogno di pensare troppo per definire una struttura. Invece, è molto più adatta ad un’evoluzione nel tempo. È possibile aggiungere nuovi campi o addirittura nidificano i dati, come ad esempio nel caso di rappresentazione JSON.
Il tempo di sviluppo
NoSQL può ridurre in modo significativo i tempi di sviluppo perché elimina la necessità di affrontare query SQL complesse per estrarre dati strutturati. In alcuni casi, si ottiene già un dato pronto per essere utilizzato in JSON.
Velocità
I database NoSQL, se utilizzati correttamente, restituiscono i dati in modo rapidissimo rispetto ad un database tradizionale. Pensiamo all’importanza di questo fattore con le applicazioni web e mobile, i frangenti in cui moltissimi hanno deciso di utilizzare i NoSQL.
Voglio iniziare subito come faccio?
Quando si parla di Big Data, spesso si parla di Apache Hadoop, ma noi – come promesso – vi parleremo di database NoSQL, sicuramente più immediati da implementare su un server dedicato o su una VPS.
I database NoSQL non sono tutti uguali e si suddividono in quattro categorie:
- Key-Valued Stores
- Column Family Stores
- Document Databases
- Graph Databases
Key-Valued Stores
Questa categoria di database consente di memorizzare e recuperare in maniera rapidissima coppie di chiave e valore, essi infatti premettono solo questo tipo di struttura:
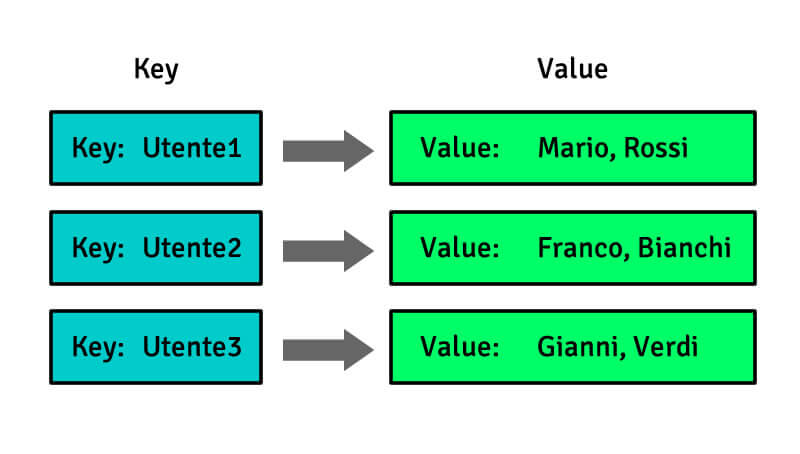 Questi database sono i più facili da implementare grazie alla loro struttura semplice e sono anche i più performanti quando la priorità sono le prestazioni in scrittura (salvataggio rapido di dati).
Questi database sono i più facili da implementare grazie alla loro struttura semplice e sono anche i più performanti quando la priorità sono le prestazioni in scrittura (salvataggio rapido di dati).
Inoltre, sono chiaramente i più adatti quando l’accesso ai dati si basa sulle chiavi.
I database più conosciuti di questo tipo sono Redis, Voldemort, Tokyo e Amazon Dynamo. Amazon è uno degli esempi e utilizza Dynamo nella gestione del proprio carrello di acquisto.
Column Family Stores
Questa famiglia di database memorizza i dati ottimizzati per la ricerca su colonne e sono progettati per gestire enormi quantità di dati distribuiti su più server. Trovano la loro migliore applicazione quando è necessario distribuire e recuperare i dati sa più server.
Uno dei database Column Family è Cassandra, sviluppato inizialmente all’interno di Facebook e poi entrato a far parte del progetto di Apache Software Foundation.
Questo è un esempio della struttura a colonne:
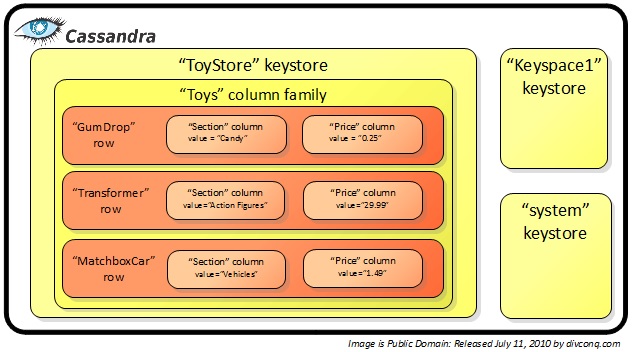 I database di questo tipo più noti e diffusi sono Cassandra, HBase e Riak. Anche Google’s Big Data fa parte di questa categoria ma non viene rilasciato al di fuori della piattaforma Google.
I database di questo tipo più noti e diffusi sono Cassandra, HBase e Riak. Anche Google’s Big Data fa parte di questa categoria ma non viene rilasciato al di fuori della piattaforma Google.
Alcuni esempi di applicazione sono:
Google Earth, Maps
The New York Times
eBay
Twitter
Facebook nella posta in arrivo (InBox)
Document Databases
Questa famiglia di database gestisce i dati in un formato documentale semi-strutturato.
In questo caso ogni record può avere una struttura diversa, l’onere di conoscere la struttura del dato, in questo caso, è delegato all’applicazione e non al database.
I dati possono essere rappresentati in formato JSON e possono contenere sotto documenti.
Questo tipo di database è indicato quando si devono salvare dati che non hanno sempre la stessa struttura o oggetti provenienti da applicazioni; inoltre, forniscono funzionalità di alta affidabilità, Sharding indicizzazione, gestione di dati geo spaziali, etc.
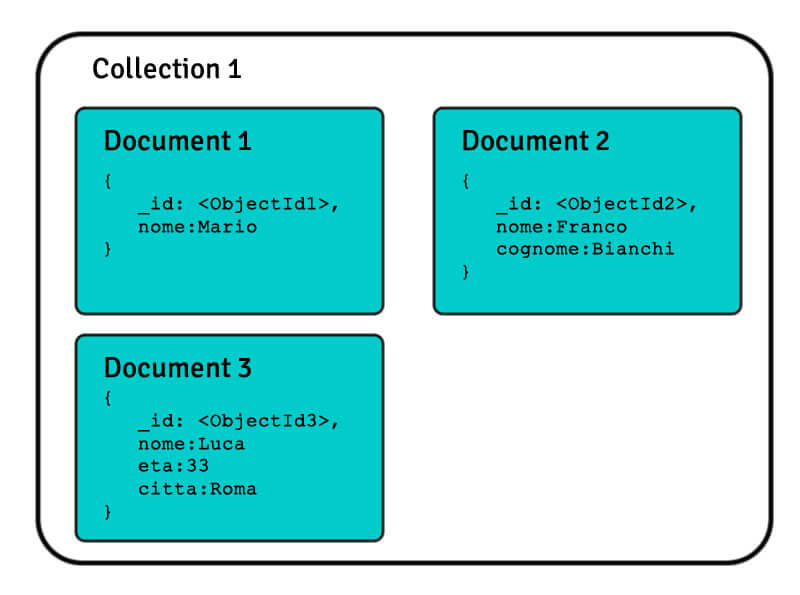 Tra i Database Documentali più utilizzati troviamo MongoDB e un altro è CouchDB.
Tra i Database Documentali più utilizzati troviamo MongoDB e un altro è CouchDB.
Esempi di applicazione pratiche sono:
LinkedIn
Dropbox Mailbox
Craigslist
The New York Times per la gestione delle fotografie
Foursquare
eBay
Leroy Merlin Italia
Graph Databases
Un database a grafo che utilizza nodi e archi per archiviare le informazioni.
Il loro utilizzo principale è rappresentato dalla gestione delle relazioni tra molti oggetti.
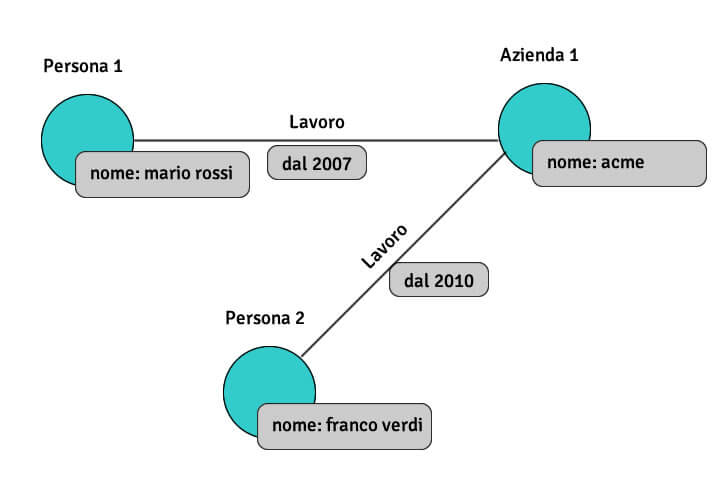 Alcuni database che fanno parte di questa categoria sono Neo4j, Infinite Graph e InfoGrid.
Alcuni database che fanno parte di questa categoria sono Neo4j, Infinite Graph e InfoGrid.
Un tipico esempio di utilizzo sono i Social Network.
Conclusioni
Abbiamo visto che la gestione dei Big Data può essere alla portata di tutti, esistono infatti strumenti Open Source utilizzabili su server dedicati o anche su server virtuali…restate connessi perché in uno dei prossimi articoli affronteremo l’installazione e i primi test con MongoDb.
